 (1).png)
Google quietly rolled out a powerful new version of Gemini last week that lets anyone edit photos using plain English commands instead of technical skills. The experimental version of Gemini 2.0 Flash with native image generation capabilities is now available to all users after being limited to testers only since last year.
Unlike most current AI image tools, this isn't just about generating new images from scratch. Google has created a system that understands existing photos well enough to modify them through natural conversation, maintaining much of the original content while making specific changes.
This is possible because Gemini 2.0 is natively multimodal, meaning it can understand both text and images simultaneously. The model converts images into tokens—the same basic units it uses to process text—allowing it to manipulate visual content using the same neural pathways it uses to understand language. This unified approach means the system doesn't need to call separate specialized models to handle different media types.
"Gemini 2.0 Flash combines multimodal input, enhanced reasoning, and natural language understanding to create images," Google said in the official announcement. “Use Gemini 2.0 Flash to tell a story and it will illustrate it with pictures, keeping the characters and settings consistent throughout. Give it feedback and the model will retell the story or change the style of its drawings.”
Google's approach differs significantly from competitors like OpenAI, whose ChatGPT can generate images using Dall-E 3 and iterate on its creations understanding natural language—but requires a separate AI model to do so. In other words, ChatGPT coordinates between GPT-V for vision, GPT-4o for language, and Dall-E 3 for image generation, instead of having one model to understand everything—which is what OpenAI expects to achieve with GPT-5.
A similar concept exists in the open-source world through OmniGen, developed by researchers at the Beijing Academy of Artificial Intelligence. Its creators envision "generating various images directly through arbitrarily multimodal instructions without the need for additional plugins and operations, similar to how GPT works in language generation."
OmniGen is also capable of altering objects, merging elements into one scene, and dealing with aesthetics. For example, we tested the model back in 2024 and were able to generate an image of Decrypt co-founder Josh Quittner hanging out with Ethereum co-founder Vitalik Buterin.
 An image generated in 2024 by OmniGen. Image: Decrypt
An image generated in 2024 by OmniGen. Image: DecryptHowever, OmniGen is a lot less user-friendly, works with smaller resolutions, requires more complex commands, and is not as powerful as the new Gemini. Still, it’s a great open-source alternative that may be interesting for some users.
Here's what we found with Google's Gemini 2.0 Flash, however.
Testing the model
We put Gemini 2.0 Flash through its paces to see how it performs across different editing scenarios. The results reveal both impressive capabilities and some notable limitations.
Realistic subjects
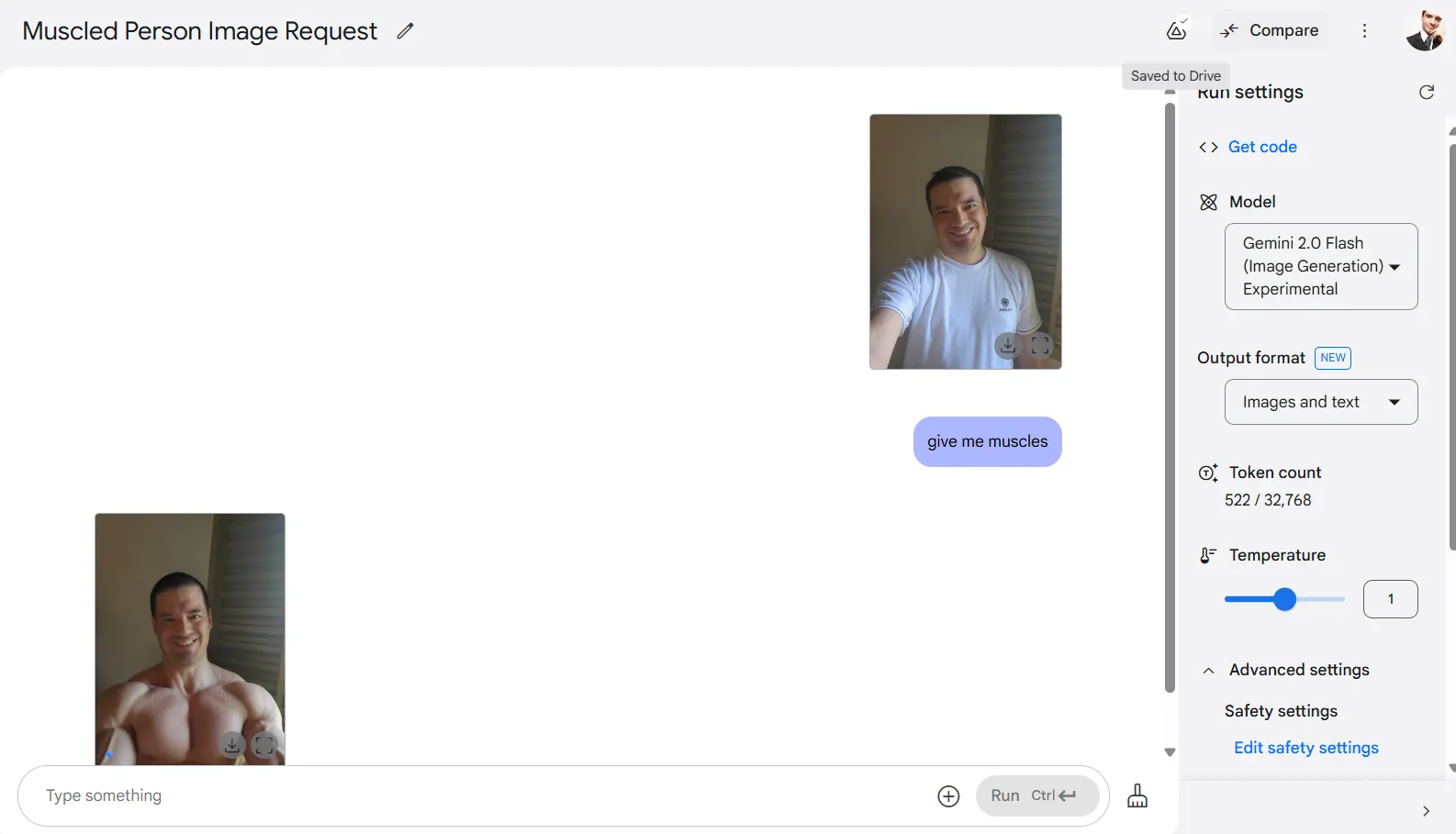
The model maintains surprising coherence when modifying realistic subjects. In my tests, I uploaded a self-portrait and asked it to add muscles. The AI delivered as requested, and while my face changed slightly, it remained recognizable.
Other elements in the photo stayed largely unchanged, with the AI focusing only on the specific modification requested. This targeted editing ability stands out compared to typical generative approaches that often recreate entire images.
The model is also censored, often refusing to edit photos of children and refusing to handle nudity, of course. After all, it's a model by Google. If you want to get naughty with adult photos, then OmniGen is your friend.
Style transformations
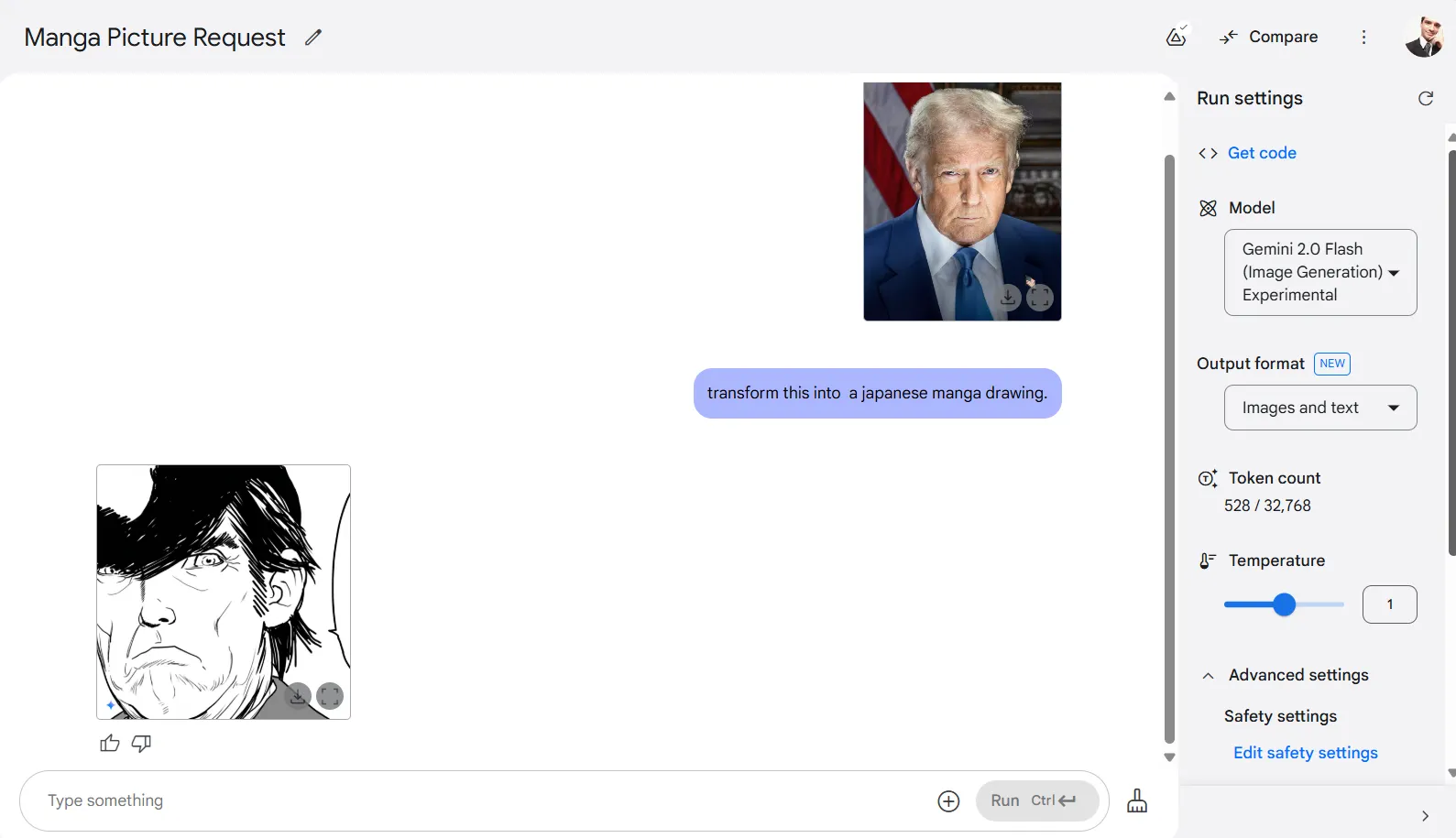
Gemini 2.0 Flash shows a very good aptitude for style conversions. When asked to transform a photo of Donald Trump into Japanese manga style, it successfully reimagined the image after a few attempts.
The model handles a wide range of style transfers—turning photos into drawings, oil paintings, or virtually any art style you can describe. You can fine-tune results by adjusting temperature settings and toggling filters, though higher temperature settings tend to produce less recognizable transformations of the original.
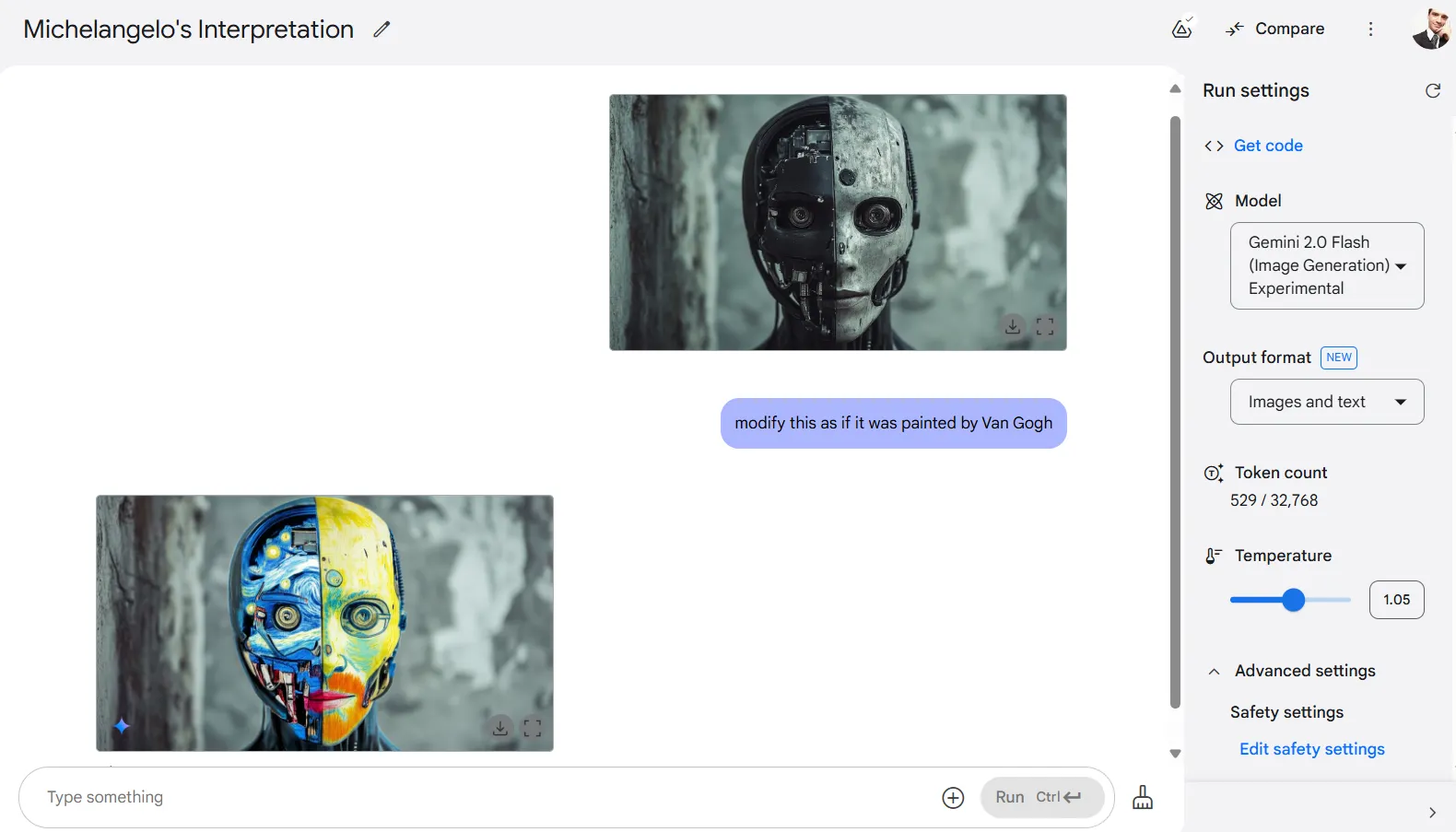
One limitation, however, happens when requesting artist-specific styles. Tests asking the model to apply the styles of Leonardo Da Vinci,
Michelangelo, Botticelli, or Van Gogh resulted in the AI reproducing actual paintings by these artists rather than applying their techniques to the source image.
After some prompt tweaks and few reruns, we were able to get a mediocre but usable result. Ideally, instead of prompting the artist, it’s better to prompt the art style.
Element manipulation
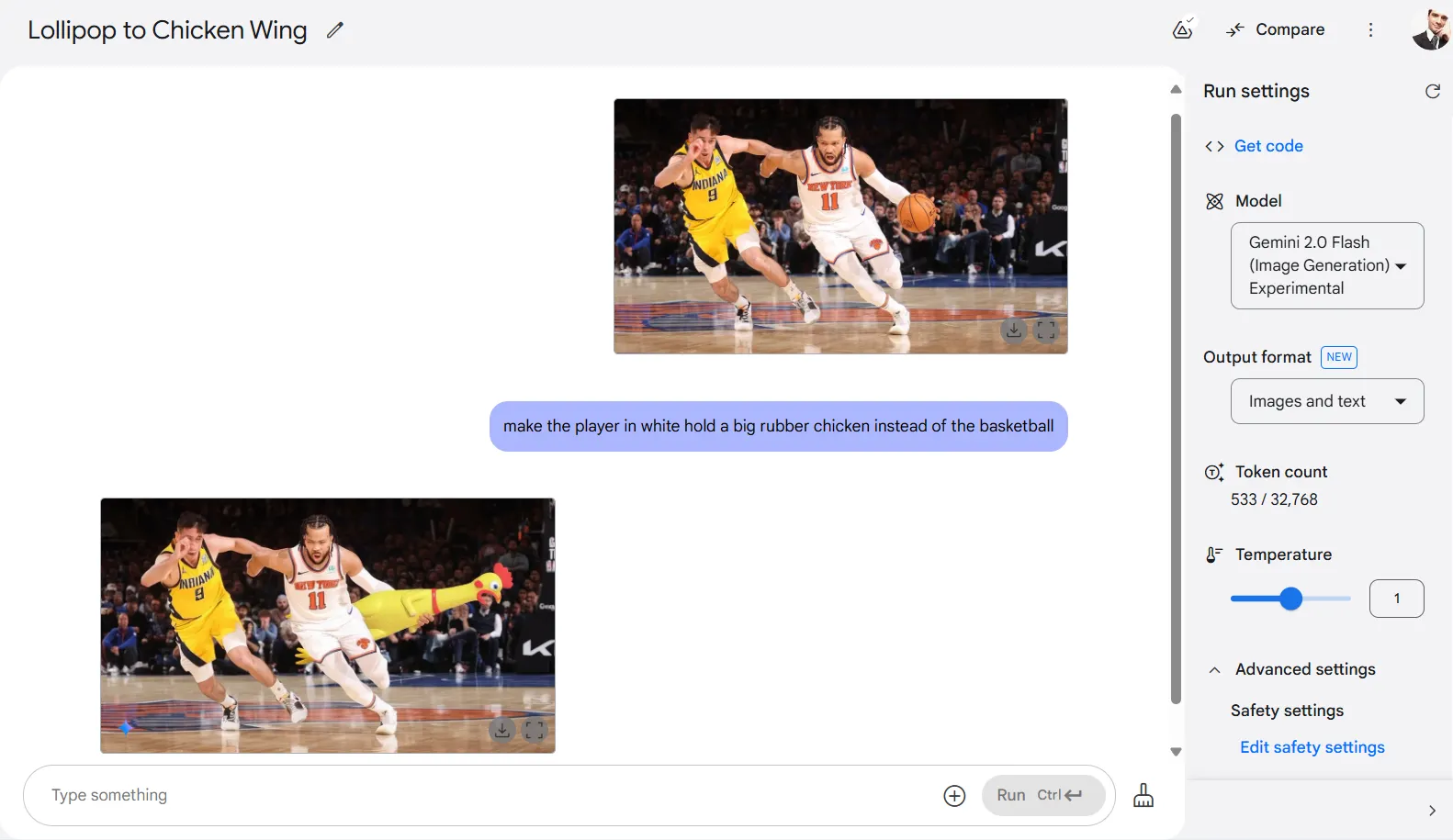
For practical editing tasks, the model truly shines. It expertly handles inpainting and object manipulation—removing specific objects when asked, or adding new elements to a composition. In one test, we prompted the AI to replace a basketball with a giant rubber chicken for some reason, and it delivered a funny yet contextually appropriate result.
Sometimes it may alter specific bits of the subjects, but this is an issue that is easily fixable with digital editing tools in a few seconds.
Honestly, we don’t know what we expected after asking it to make basketball players fight for a rubber chicken.
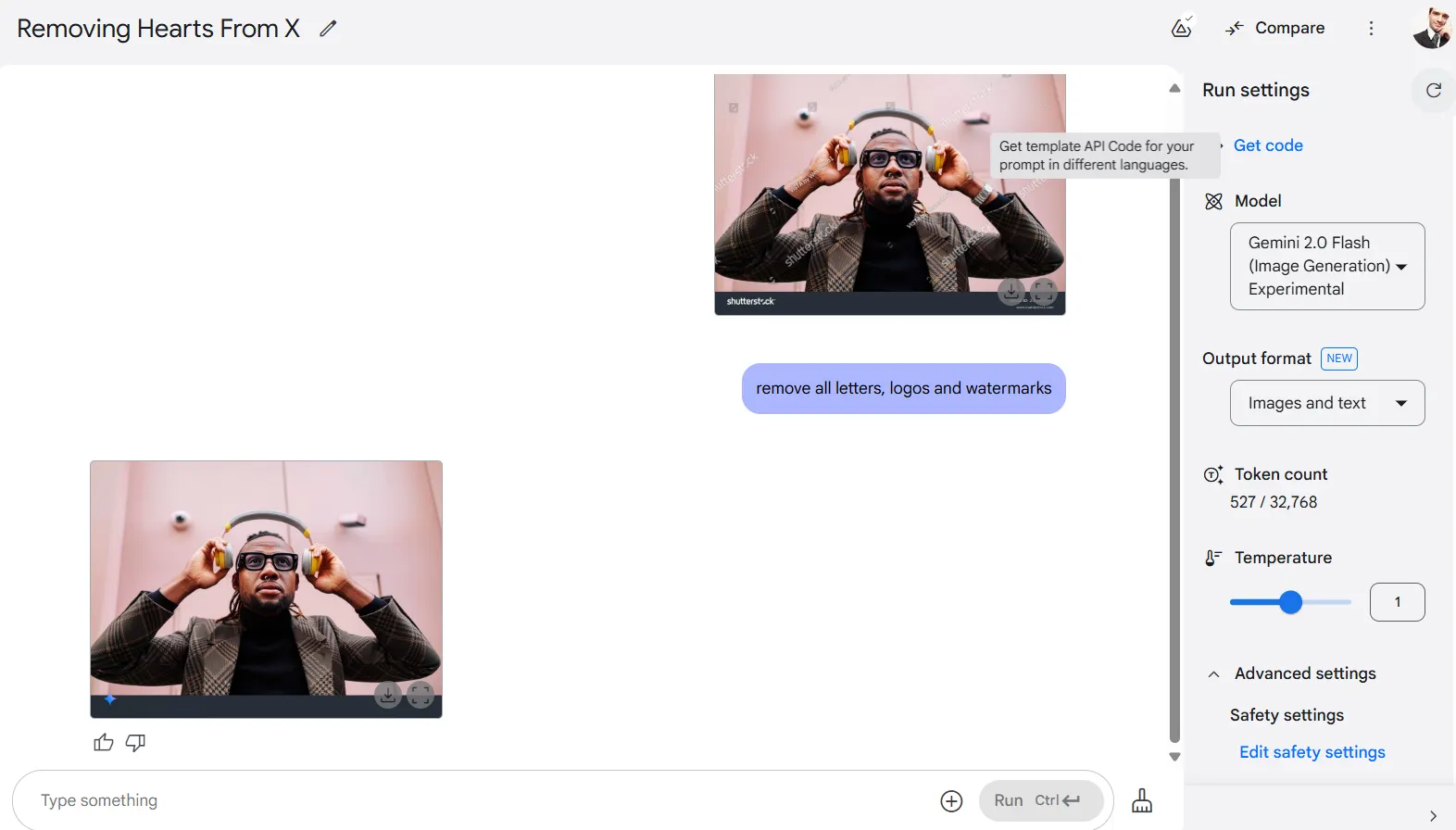
Perhaps most controversially, the model is very good at removing copyright protections—a feature that was widely talked about on X. When we uploaded an image with watermarks and asked it to delete all letters, logos, and watermarks, Gemini produced a clean image that appeared identical to the un-watermarked original.
Perspective changes
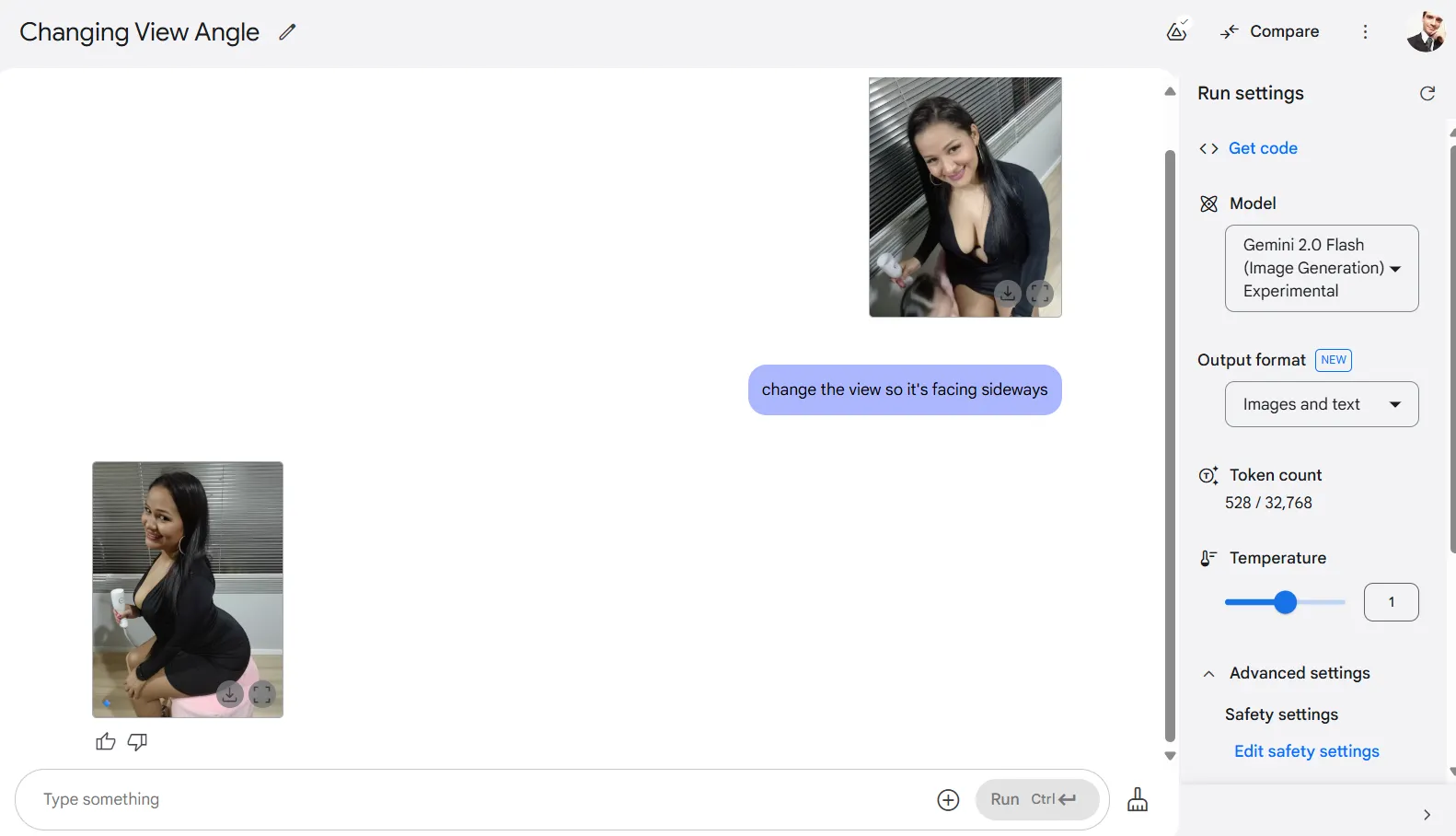
One of the most technically impressive feats is Gemini's ability to change perspective—something mainstream diffusion models cannot do. The AI can reimagine a scene from different angles, though the results are essentially new creations rather than precise transformations.
While perspective shifts don't deliver perfect results—after all, the model is conceptualizing 100% of the image while rendering it from new viewpoints—they represent a significant advance in AI's understanding of three-dimensional space from two-dimensional inputs.
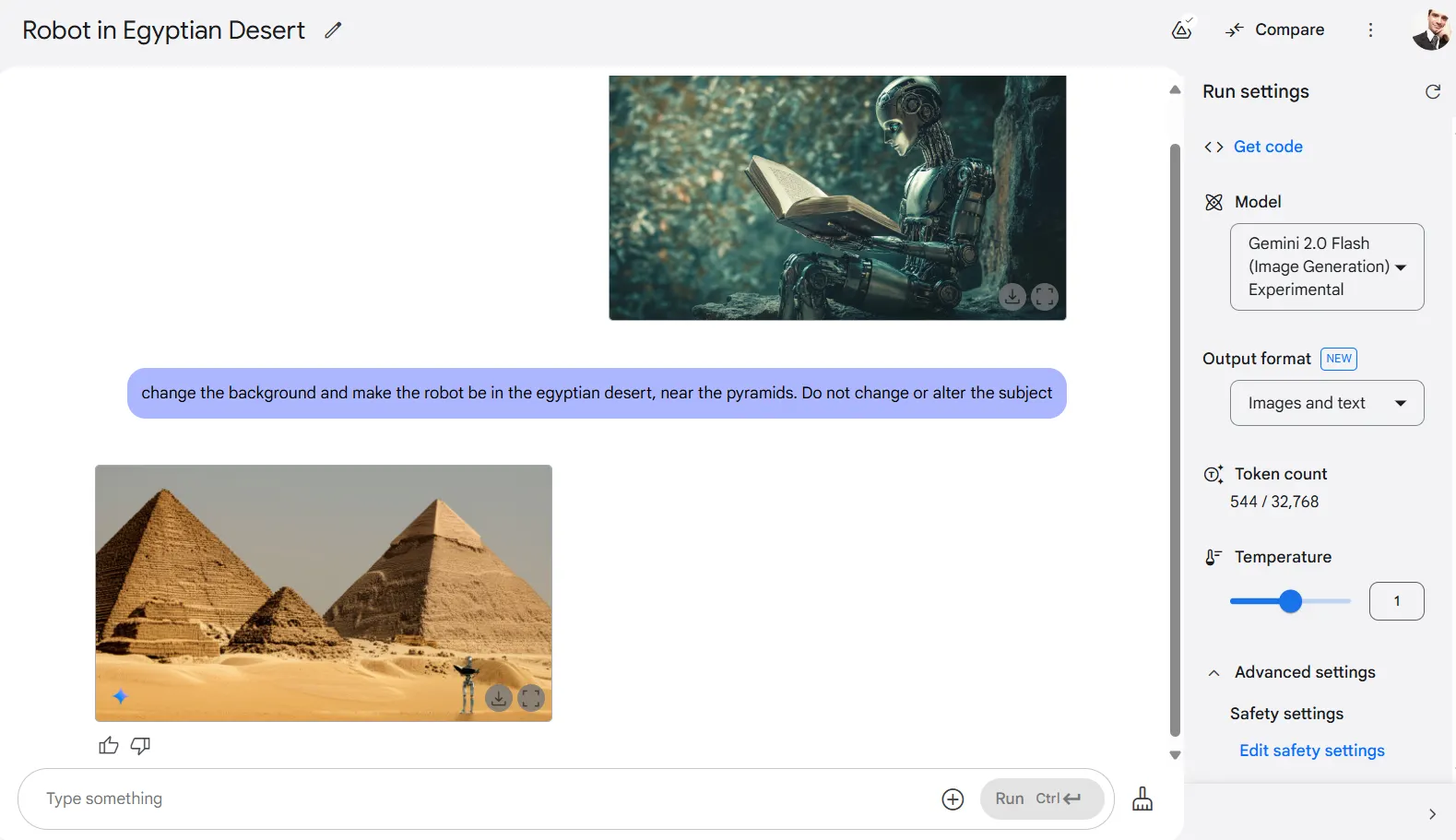
It is also important to have proper phrasing when asking the model to deal with backgrounds. Usually it tends to modify the whole picture, making the composition look totally different.
For example, in one test, we asked Gemini to changed the background of a photo, making a sitting robot be in Egypt instead of its original locale. We asked Gemini not to alter the subject. However, the model was not able to handle this specific task properly, and instead provided a brand new composition featuring the pyramids, with a robot standing but not as the primary subject.
Another fault we found is that the model is capable of iterating several times with one image, but the quality of the details will decrease the more iterations it goes through. So it’s important to keep in mind that there may be a noticeable degradation in quality if you go too overboard with the edits.

The experimental model is now available to developers through Google AI Studio and the Gemini API across all supported regions. It’s also available on Hugging Face for users who are not comfortable with sending their information to Google.
Overall this seems one of those hidden gems from Google, much like NotebookLM. It does something other models cannot do and is good enough at it, but still not a lot of people talk about it. It is definitely worth the try for users who want to have fun and see the potential of generative AI in image editing.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.








 English (US) ·
English (US) ·